October 8, 2018 - 4 min read
Data strategy : helping developpers with AI

Developers and many technical jobs write code for a living. Can you help a developer with Artificial intelligence ?
Spending a fair amount of time, conceiving and writing code, I keep falling on the same time-consuming task : debugging and correct typo-like mistakes. Even after close to a decade of code writing, I still keep having these silly tiny mistakes that keep on slowing me down in the development process every once in a while.
As a Data scientist, I like to look for opportunities to improve. In a fictional version, I could try to imagine a system which would code for me once I have done the design. This sounds like a daunting task. It is like asking a friend to write the novel you planned. It is not going to be exactly as you designed it. So how would I design an AI-based system that could help me to code better ?
From spellcheckers to linters
Traditionally, spellcheckers simply compare if a word exists in a dictionary. Microsoft has pushed the limit further by adding advanced spellcheckers / edition capabilities to Microsoft Word that are built on AI-based tools source. The goal in this case is to provide support in text writing beyond the obvious and suggest similar words to enrich the text.
Lint tools are basically programmers spell checkers. They are based on a certain amount of rules extracted from standards (PEP8 for Python aficionados) which are guidelines on how you should write code in a given language. Nowadays, linters are good on obvious mistakes, but what about helping advanced programmers too ? Suggesting better general code architectures ?
How to design a code suggestion system based on machine learning ? The point is not an autocompletion system that can only suggest the next “word” but large code structure suggestions for languages such as Python.
Getting enough of the right data
The first step will be to get data. In a preliminary step, I would try to clone many Github repositories in order to have large amounts of developed projects in a given langage.
Cloning repositories, do not ensure data quality. Many of these repositories are tests, codes in development and so on. In order to feed a learning algorithm, I would then try to see if some patterns emerges from branch names in order to find recurring patterns that indicate “testing” situations.
Model selection process for an AI-based linter
Aside from programming specifics, code files are basically text files. So in order to model what is contained in them (sequences of characters), I could test models such as recurrent neural networks. The general idea would be to train the neural network to basically guess what are the following X characters. The complexity arise from defining how long X would be.
In the end, once you commit your modifications (use Version Control Software for everything you code !), you could imagine a function that indicates you regions in your code that are not optimal.
Generally speaking, I expect the previous modelling strategy to fail : too complex for a starter. In order to attempt something that could actually work, I would try to have first a working code classifier. This classifier could predict the general quality of a given piece of code. For that, you need to have a representation of the code that could fit into a classifier with a class attribute (e.g. good, average, bad). It means, one has to transform every code sequence into a vector representation that could be fed into something like a boosted tree classifier. Then, the annotation of the code quality would be the painful section of the work, going through many examples and attributing a quality label to the data in order to have a training dataset.
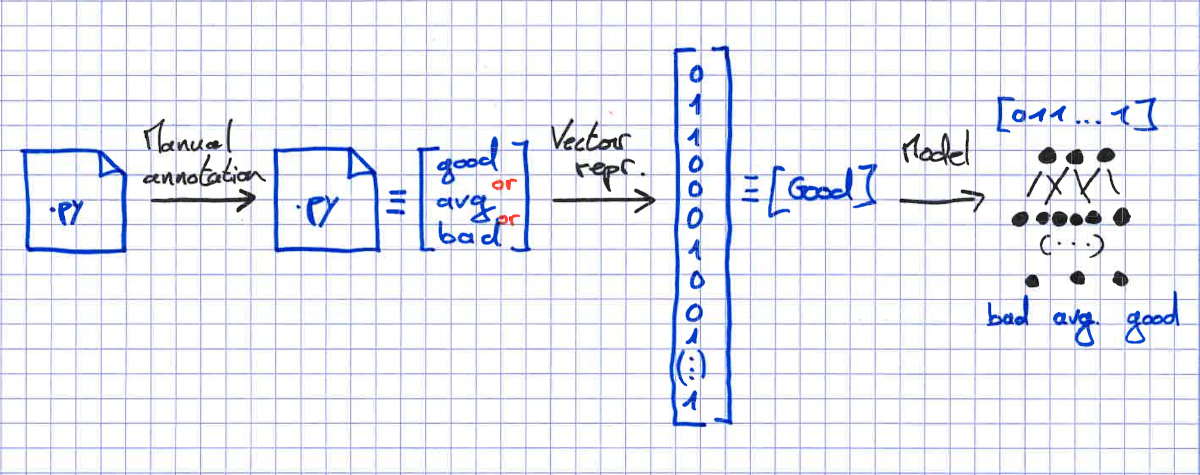
Some might ask why going for a boosted trees strategy and not a neural network ? Neural networks, in order to actually deliver their full capacity, need a lot of annotated data. In a preliminary run, I think it would be easier to try boosted trees because they require less data before delivering results you can analyse.
If this works, you can start to make something more complex. Add elements to make the model better (number of code lines, comment lines count, …), think about pseudo-labelling to have more data to train, stack multiple models, … and finally integrate this into a global IT.
On the long run, you could imagine a system that would be able to make recommendations on how to make your code better. But like very often in data science projects, you need to start simple and iterate to get there.
Why care about code quality ?
If running a one shot (proof of concept) trial, one need to take care of code quality with moderate concern. On the other hand, if you develop code that needs to run in production and be maintainable for years, this is a key issues.
On long term projects, it often happens that the developer updating a solution is not necessarily the one who developped it in the first place. Anything you can do to easen the entry/reading into code is of interest. Time wasted is wasted money.
This code quality indicator could be used in two different settings. In the first, during original code developpement, it can help to self-assess the quality of produced code and deliver better initial code, requiring less time of code review by senior profiles. Second, on a “house code cleaning” operation, it could be used to prioritize which code needs review and which one is clear enough.
As an indication of such interest, Embold, initially developped by Accelere, offers a solution that enables to quickly assess code quality and review priorities. It appears that they use AI embeded in a proprietary solution.
Conclusion
Finally, would I blindly use the model that comes from this strategy ? Probably not. One of the key concerns here is the data annotation. In order to have a model that has been trained on quality data, I would ideally have senior developper assess code cross organisation and country. Like any tool, you have to be aware of its bias and fix them when possible.